
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- JavaScript
- 깃
- 타입스크립트
- 웹디실기
- jQuery
- PROJECT
- 웹디자인기능사
- 실기
- 생활코딩
- 세로메뉴바
- 슬라이드전환
- web
- 코딩독학
- JS
- 자바스크립트
- 프론트엔드
- 웹퍼블리셔
- react
- 비전공자
- 리액트
- HTML
- 렛츠기릿자바스크립트
- Supabase
- git
- 코드공유
- 연산자
- 정보처리기사
- github
- 웹디자인기능사실기
- CSS
- Today
- Total
코딩하는라민
[Web] 웹 브라우저가 어떻게 동작하는가? 본문
[Web] 웹 브라우저가 어떻게 동작하는가?
이번 포스팅에서는 주소창에 github.com 을 입력하고 브라우저 화면에 github.com 페이지가 표시될 때까지 어떤 일이 일어나는지 확인해볼 것이다.
🧶 브라우저의 동작 원리
우리가 자주 사용되는 주요 브라우저에는 Chrome, Internet Explorer, Firefox, Safari, Opera 이 있다. 그 중에서 Chrome, Firefox, Safari 가 전 세계 데스크톱 브라우저 사용량의 71%를 차지할 만큼 많이 사용된다.
브라우저는 웹 리소스를 서버에 요청하고, 브라우저에 표시하는 기능이 있다. 웹 리소스는 보통 HTML 문서이다. 하지만 이 외에도 PDF 문서나 이미지 또는 기타 콘텐츠 유형일 수도 있다.
이 리소스의 위치는 사용자가 URI (Uniform Resource Identifier) 를 사용하여 지정할 수 있다.
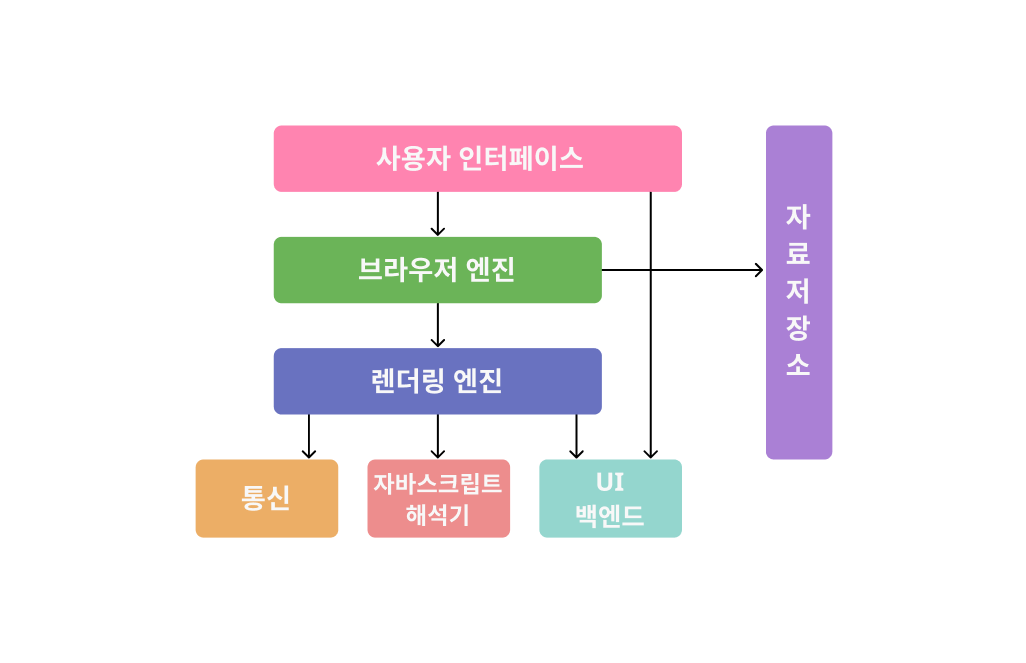
| 브라우저의 구조 | |
| 사용자 인터페이스 | 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등의 요청한 페이지를 보여주는 창 외의 모든 부분을 말한다. |
| 브라우저 엔진 | 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어한다. |
| 렌더링 엔진 | HTML, CSS 를 파싱하여 요청한 콘텐츠를 화면에 표시한다. |
| 통신 | HTTP 요청과 같은 네트워크 호출 시 사용된다. |
| 자바스크립트 해석기 | javascript 코드를 해석하고 실행한다. |
| UI 백엔드 | 콤보 박스와 같은 장치를 그린다. |
| 자료 저장소 | 쿠키를 저장하는 것과 같이 모든 종류의 자원을 디스크에 저장. 또한 localStorage, IndexedDB, WebSQL 및 FileSystem과 같은 저장 메커니즘을 지원. |
Chrome 브라우저는 렌더링 엔진의 여러 인스턴스를 각 탭당 하나씩 실행한다.
✒️ 사용자 인터페이스

✒️ 브라우저 엔진
사용자 인터페이스의 주소 입력창에 github.com 을 입력했다고 하자. 그 다음에는 브라우저 엔진이 작동하게 된다.
브라우저 엔진은 입력받은 주소값에 해당하는 데이터를 우선 자료 저장소에서 찾는다.
만약 자료 저장소에 데이터가 없다면 입력받은 URI 값을 렌더링 엔진에 전달해준다.
✒️ 자료 저장소
자료 저장소를 거치지 않고 URI를 입력할 때마다 서버로 가서 데이터를 받아오게 된다면, 불필요한 메서드 통신이 발생한다.
다시말해 같은 URI 를 여러 번 입력했을 때, 계속해서 서버로부터 응답을 요청하기 때문에 낭비가 생긴다는 것이다.
따라서 자료 저장소로부터 자주 다운로드 받는 데이터를 저장해두고, 사용할 때마다 서버로부터 데이터를 요청(통신)할 필요 없이 바로 받아올 수 있다.
이것을 캐싱이라고 한다.
✒️ 통신
서버에게 HTTP 요청을 하고, 서버로부터 응답받은 데이터(HTML, CSS, JS)를 렌더링 엔진에 전달해준다.
✒️ 자바스크립트 해석기
자료 저장소 또는 통신 단계를 거쳐 데이터를 응답받은 렌더링 엔진은 javascript 해석기를 통해 javascript 를 파싱하게 된다.
Chrome 에서는 V8 이라는 javascript 엔진을 사용한다. 이것을 통해 javascript 를 파싱하게 되는 것이다.
✒️ 렌더링 엔진
렌더링 엔진은 요청된 콘텐츠를 브라우저 화면에 표시하는 역할을 한다. 기본적으로 렌더링 엔진은 HTML, XML 문서, 이미지를 표시할 수 있다.
브라우저마다 다른 렌더링 엔진을 사용하는데 firefox 는 Gecko 엔진을 사용하고, Safari, Chrome, Opera 브라우저는 WebKit 엔진을 사용한다. Chrome 과 Opera 는 WebKit 의 fork 인 Blink 를 사용한다.
* WebKit 은 리눅스 플랫폼용 엔진으로 시작해 맥, 윈도우를 지원하도록 apple 에서 수정한 오픈 소스 렌더링 엔진이다.
렌더링 엔진은 네트워크 계층에서 요청된 문서의 내용을 가져온다. 이후에는 다음과 같은 렌더링 엔진의 기본 흐름을 따른다.
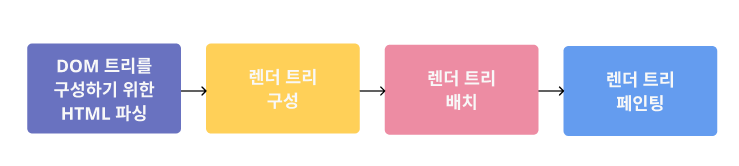
| 렌더링 엔진의 기본 흐름 | |
| HTML 파싱 | 렌더링 엔진은 HTML 문서의 구문 분석(파싱) 파싱된 요소를 '콘텐츠 트리'라는 트리의 'DOM 노드'로 변환 외부 CSS 파일, 스타일 요소도 같이 파싱 스타일 정보, HTML 표시 규칙, javascript 파싱 결과물은 '렌더 트리'를 만드는데 사용한다. |
| 렌더 트리 생성 |
HTML, CSS 를 파싱해서 만들어진 '렌더 트리'에는 색상, 면적과 같은 시각적 속성 포함하며, 이것을 정해진 순서대로 렌더링한다. |
| 렌더 트리 배치(레이아웃) |
DOM node 는 배치 정보를 갖고 있다. 화면에 정해진 순서대로 배치하는 '레이아웃 단계'를 거치게 된다. 생성 과정이 끝났을 때 이루어지며 노드가 화면에 정확한 위치에 표시되는 것을 의미한다. |
| 렌더 트리 페인팅 |
node 배치가 끝나면 UI 백엔드에서 렌더 트리의 각 node 들을 순회하고, 페인팅 작업을 하여 그리기를 완료하게 된다. |
HTML 파싱 단계와 렌더트리 구축, 배치, 페인팅 단계는 병렬적으로 일어난다.
즉 DOM 트리가 완성이 되는 순간 바로바로 렌더 트리가 구축이 되고 그려지게 된다.
따라서 사용자는 DOM 트리가 완벽하게 구축될 때까지 기다릴 필요 없이 렌더 트리가 그려짐으로 인해서 브라우저가 렌더링될 때 위에서부터 조금씩 표시하게 되는 것을 볼 수 있다.
사용자 경험을 위해 렌더링 엔진은 콘텐츠를 빠르게 화면에 표시하는 것이다. 즉, 렌더 트리 빌드, 레이아웃을 시작하기 전에 모든 HTML이 파싱될 때까지 기다리지 않는다!
* DOM : 웹 브라우저가 HTML 페이지를 인식하는 방식
| DOM tree | Lender tree | |
| 자식 요소 | ➡️ DOM node | ➡️ Lender object |
✒️ UI 백엔드
렌더링 엔진에서 생성된 렌더 트리를 브라우저에 그리는 역할을 담당한다.
✒️ 웹킷의 동작 구조

HTML을 파싱해서 Dom tree 를 생성하면 javascript가 조작할 수 있게 된다. 즉, 사용자와 상호작용을 할 수 있게 되는 것이다.
DOM 트리를 생성하는 동시에 이것을 스타일 규칙(CSSOM)과 Attachment 를 하게 되면서 렌더 트리를 구축하게 된다.
하지만 모든 DOM node 가 렌더 트리로 생성되는 것은 아니다. 예를 들어 head 태그의 경우에는 브라우저에 직접적으로 렌더링되지 않는다.
html 태그와 , body 태그의 DOM node 는 렌더 트리의 root로써 render view 라고 부른다. 이들 또한 render object 로 구성된다. 이러한 render view 아래에 차곡차곡 추가하면서 렌더 트리를 구축하게 된다.
🧶 페이지 리소스 정보 확인
주소창에 github.com 을 입력하고 들어가서 개발자 도구(F12)의 네트워크 탭을 들어가보면.
처음에는 아무 것도 뜨지 않는데 이때 F5를 누르면 다운받은 리소스들이 뜨게된다.
그 상태에서 맨 아래에 보면 페이지 리소스들에 대한 정보가 나온다.

- 다운로드 요청 개수
- 수신한(다운로드한) 데이터 크키
- 웹 페이지 총 크기
- 다운로드 소요시간
- HTML 로드 시간
- 웹 페이지 렌더링 완료 시간
132개의 다운로드를 했으며, 그 크기는 1.7MB 이고 웹 페이지의 총 크기는 4.6 MB이다. 다운로드하는 데 소요된 시간은 4.88초이며, HTML 로드 시간은 1.28초, 웹페이지를 렌더링하는 데 완료된 시간은 1.77초이다.
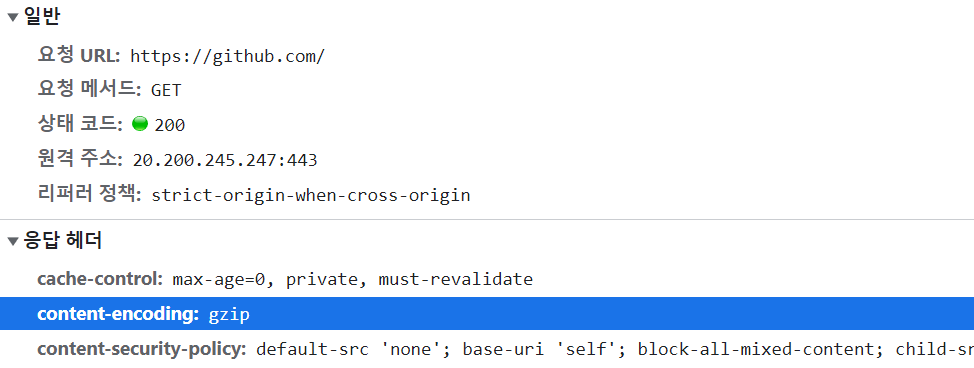
다운로드한 데이터의 크기와 웹 페이지의 총 크기가 다른 이유는 웹 브라우저가 압축된 리소스를 다운받기 때문이다.
압축을 했는지 알 수 있는 방법은 응답 헤더의 'content-encoding' 부분을 확인하면 된다. 압축된 리소스를 다운받았다면 gzip 이 있을 것이고 그렇지 않다면 gzip이 없을 것이다.
참고 :
브라우저 작동 원리 설명 강의 참고 ➡️
✨✨ https://youtu.be/oLC_QYPmtS0(1편:브라우저 동작 과정 전반적인 설명),
✨✨✨ https://youtu.be/EBe-OHkf9w8(2편:렌더링 엔진 작동 과정 자세한 설명)
✨브라우저의 작동 원리(요약본) ➡️ https://gyoogle.dev/blog
브라우저의 기본 원리 설명 강의 참고 ➡️ https://youtu.be/cCbAJY1riDc
등을 공부하고, 간단하게 정리한 내용입니다. 잘못된 부분이나 문제되는 점이 있으면 댓글 부탁드립니다.
'Web' 카테고리의 다른 글
| [Web] HTTP Request Methods 란? (2) | 2023.04.30 |
|---|---|
| [Web] 쿠키(Cookie)와 세션(Session) 이란? (1) | 2023.04.29 |

